Core Concepts¶
Below are some core concepts to understand before building pipelines in Jenkins.
- Pipeline as Code
- Step
- Master vs Nodes
- Checkout
- Workspace
- Stage
- Sandbox and Script Security
- Java vs. Groovy
- Env (object)
- Stash & archive
- Credentials
- Tools & Build Environment
- Pipeline Syntax Page
Terminology¶
The terminology used in this page is based upon the terms used by Cloudbees as related to Jenkins.
If in doubt, please consult the Jenkins Glossary.
Pipeline as Code¶
Step¶
A single task; fundamentally steps tell Jenkins what to do inside of a Pipeline or Project.
Consider the following piece of pipeline code:
node {
timestamps {
stage ('My FIrst Stage') {
if (isUnix()) {
sh 'echo "this is Unix!"'
} else {
bat 'echo "this is windows"'
}
}
}
}
The only execution that happens (almost) exclusively on the node (or build slave) are the isUnix(), sh and bat shell commands.
Those specific tasks are the steps in pipeline code.
Master vs Nodes¶
There are many things to keep in mind about Pipelines in Jenkins. By far the most important are those related to the distinction between Masters and Nodes.
Aside from the points below, the key thing to keep in mind: Nodes (build slaves) are designed to executes task, Masters are not.
-
Except for the steps themselves, all of the Pipeline logic, the Groovy conditionals, loops, etc execute on the master. Whether simple or complex! Even inside a node block!
-
Steps may use executors to do work where appropriate, but each step has a small on-master overhead too.
-
Pipeline code is written as Groovy but the execution model is radically transformed at compile-time to Continuation Passing Style (CPS).
-
This transformation provides valuable safety and durability guarantees for Pipelines, but it comes with trade-offs:
- Steps can invoke Java and execute fast and efficiently, but Groovy is much slower to run than normal.
- Groovy logic requires far more memory, because an object-based syntax/block tree is kept in memory.
-
Pipelines persist the program and its state frequently to be able to survive failure of the master.
Source: Sam van Oort, Cloudbees Engineer
Node¶
A machine which is part of the Jenkins environment and capable of executing Pipelines or Projects. Both the Master and Agents are considered to be Nodes.
Master¶
The central, coordinating process which stores configuration, loads plugins, and renders the various user interfaces for Jenkins.
What to do?¶
So, if Pipeline code can cause big loads on Master, what should we do than?
- Try to limit the use of logic in your groovy code
- Avoid blocking or I/O calls unless explicitly done on a slave via a Step
- If you need heavy processing, and there isn't a Step, create either a
- plugin
- Shared Library
- Or use a CLI tool via a platform independent language, such as Java or Go
Tip
If need to do any I/O, use a plugin or anything related to a workspace, you need a node. If you only need to interact with variables, for example for an input form, do this outside of a node block. See Pipeline Input for how that works.
Workspace¶
A disposable directory on the file system of a Node where work can be done by a Pipeline or Project. Workspaces are typically left in place after a Build or Pipeline run completes unless specific Workspace cleanup policies have been put in place on the Jenkins Master.
The key part of the glossary entry there is disposable directory. There are absolutely no guarantees about Workspaces in pipeline jobs.
That said, what you should take care of:
- always clean your workspace before you start, you don't know the state of the folder you get
- always clean your workspace after you finish, this way you're less likely to run into problems in subsequent builds
- a workspace is a temporary folder on a single node's filesystem: so every time you use
node{}you have a new workspace - after your build is finish or leaving the node otherwise, your workspace should be considered gone: need something from? stash or archive it!
Checkout¶
There are several ways to do a checkout in the Jenkins pipeline code.
In the groovy DSL you can use the Checkout dsl command, svn shorthand or the git shorthand.
Danger
If you use a pipeline from SCM, multi-branch pipeline or a derived job type, beware! Only the Jenkinsfile gets checked out. You still need to checkout the rest of your files yourself!
Tip
However, when using pipeline from SCM, multi-branch pipeline or a derived job type. You can use a shorthand: checkout scm. This checks out the scm defined in your job (where the Jenkinsfile came from).
Stage¶
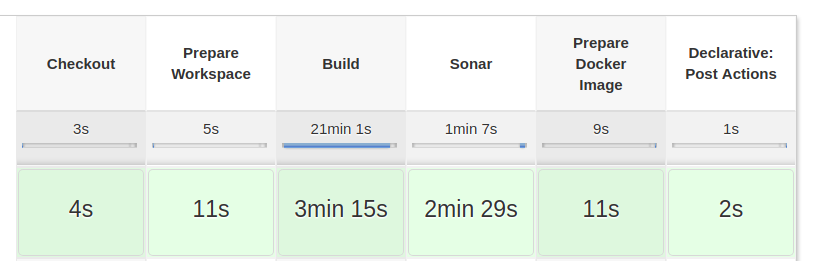
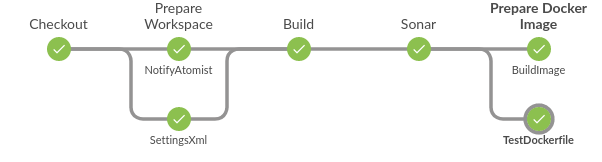
Stage is a step for defining a conceptually distinct subset of the entire Pipeline, for example: "Build", "Test", and "Deploy", which is used by many plugins to visualize or present Jenkins Pipeline status/progress.
The stage "step" has a primary function and a secondary function.
- Its primary function is to define the visual boundaries between logically separable parts of the pipeline.
- For example, you can define SCM, Build, QA, Deploy as stages to tell you where the build currently is or where it failed.
- The secondary function is to provided a scope for variables.
- Just like most programming languages, code blocks are a more than just syntactic sugar, they also limit the scope of variables.
node {
stage('SCM') {
def myVar = 'abc'
checkout scm
}
stage('Build') {
sh 'mvn clean install'
echo myVar # will fail because the variable doesn't exist here
}
}
Stages in classic view¶
Stages in Blue Ocean view¶
Sandbox and Script Security¶
In Jenkins some plugins - such as the pipeline plugin - allow you to write groovy code that gets executed on the master.
This means you could run code on the master that accesses the host machine with the same rights as Jenkins. As is unsafe, Jenkins has some guards against this in the form the sandbox mode and the script security.
When you create a pipeline job, you get a inline code editor by default. If you're an administrator you get the option to turn the "sandbox" mode of.
If you use a pipeline from SCM or any of the higher abstraction pipeline job types (Multibranch Pipeline, BitBucket Team) you are always running in sandbox mode.
When you're in sandbox mode, your script will run past the script security. This uses a whitelisting technique to block dangerous or undesired methods, but is does so in a very restrictive manner.
It could be you're doing something that is safe but still gets blocked. An administrator can then go to the script approval page (under Jenkins Administration) and approve your script.
For more details, please consult Script Security plugin page.
Example error¶
org.jenkinsci.plugins.scriptsecurity.sandbox.RejectedAccessException: unclassified staticMethod org.tmatesoft.svn.core.internal.io.dav.DAVRepositoryFactory create org.tmatesoft.svn.core.SVNURL
at org.jenkinsci.plugins.scriptsecurity.sandbox.groovy.SandboxInterceptor.onStaticCall(SandboxInterceptor.java:138)
at org.kohsuke.groovy.sandbox.impl.Checker$2.call(Checker.java:180)
at org.kohsuke.groovy.sandbox.impl.Checker.checkedStaticCall(Checker.java:177)
at org.kohsuke.groovy.sandbox.impl.Checker.checkedCall(Checker.java:91)
at com.cloudbees.groovy.cps.sandbox.SandboxInvoker.methodCall(SandboxInvoker.java:16)
at WorkflowScript.run(WorkflowScript:12)
at ___cps.transform___(Native Method)
Tip
There are three ways to deal with these errors.
- go to manage jenkins → script approval and approve the script
- use a Shared Library
- use a CLI tool/script via a shell command to do what you need to do
Java vs. Groovy¶
The pipeline code has to be written in groovy and therefor can also use java code. Two big difference to note:
- the usage of double quoted string (gstring, interpreted) and single quoted strings (literal)
def abc = 'xyz' # is a literalecho '$abc' # prints $abcecho "$abc" # prints xyz
- no use of ;
Unfortunately, due to the way the Pipeline code is processed, many of the groovy features don't work or don't work as expected.
Things like the lambda's and for-each loops don't work well and are best avoided. In these situations, it is best to keep to the standard syntax of Java.
For more information on how the groovy is being processed, it is best to read the technical-design.
Env (object)¶
The env object is an object that is available to use in any pipeline script.
The env object allows you to store objects and variables to be used anywhere during the script. So things can be shared between nodes, the master and nodes and code blocks.
Why would you want to use it? As in general, global variables are a bad practice. But if you need to have variables to be available through the execution on different machines (master, nodes) it is good to use this.
Also the env object contains context variables, such as BRANCH_NAME, JOB_NAME and so one. For a complete overview, view the pipeline syntax page.
Don't use the env object in functions, always feed them the parameters directly. Only use it in the "pipeline flow" and use it for the parameters of the methods.
node {
stage('SCM') {
checkout scm
}
stage('Echo'){
echo "Branch=$env.BRANCH_NAME" // will print Branch=master
}
}
Stash & archive¶
If you need to store files for keeping for later, there are two options available stash and archive.
Both should be avoided as they cause heavy I/O traffic, usually between the Node and Master.
For more specific information, please consult the Pipeline Syntax Page.
Stash¶
Stash allows you to copy files from the current workspace to a temp folder in the workspace in the master. If you're currently on a different machine it will copy them one by one over the network, keep this in mind.
The files can only be retrieved during the pipeline execution and you can do so via the unstash command.
node('Machine1') {
stage('A') {
// generate some files
stash excludes: 'secret.txt', includes: '*.txt', name: 'abc'
}
}
node('Machine2') {
stage('B') {
unstash 'abc'
}
}
Saves a set of files for use later in the same build, generally on another node/workspace. Stashed files are not otherwise available and are generally discarded at the end of the build. Note that the stash and unstash steps are designed for use with small files. For large data transfers, use the External Workspace Manager plugin, or use an external repository manager such as Nexus or Artifactory.
Archive & archiveArtifacts¶
Archives build output artifacts for later use. As of Jenkins 2.x, you may use the more configurable archiveArtifacts.
With archive you can store a file semi-permanently in your job. Semi as the files will be overridden by the latest build.
The files you archive will be stored in the Job folder on the master.
One usecase is to save a log file from a build tool.
node {
stage('A') {
try {
// do some build
} finally {
// This step should not normally be used in your script. Consult the inline help for details.
archive excludes: 'useless.log', includes: '*.log'
// Use this instead, but only for permanent files, or external logfiles
archiveArtifacts allowEmptyArchive: true, artifacts: '*.log', excludes: 'useless.log', fingerprint: true, onlyIfSuccessful: true
}
}
}
Credentials¶
In many pipelines you will have to deal with external systems, requiring credentials.
Jenkins has the Credentials API which you can also utilize in the pipeline.
You can use do this via the Credentials and Credentials Binding plugins, the first is the core plugin the second provides the integration for the pipeline.
The best way to generate the required code snippet, is to go to the pipeline syntax page, select withCredentials and configure what you need.
node {
stage('someRemoteCall') {
withCredentials([usernameColonPassword(credentialsId: 'someCredentialsId', variable: 'USRPASS')]) {
sh "curl -u $env.USRPASS $URL"
}
}
}
For more examples, please consult Cloudbees' Injecting-Secrets-into-Jenkins-Build-Jobs blog post.
Tools & Build Environment¶
Jenkins would not be Jenkins without the direct support for the build tools, such as JDK's, SDK's, Maven, Ant what have you not.
So, how do you use them in the pipeline?
Unfortunately, this is a bit more cumbersome than it is in a freestyle (or legacy) job.
You have to do two things:
- retrieve the tool's location via the tool DSL method
- set the environment variables to suit the tool
node {
stage('Maven') {
String jdk = tool name: 'jdk_8', type: 'jdk'
String maven = tool name: 'maven_3.5.0', type: 'maven'
withEnv(["JAVA_HOME=$jdk", "PATH+MAVEN=${jdk}/bin:${maven}/bin"]) {
sh 'mvn clean install'
}
// or in one go
withEnv(["JAVA_HOME=${ tool 'jdk_8' }", "PATH+MAVEN=${tool 'maven_3.5.0'}/bin:${env.JAVA_HOME}/bin"]) {
sh 'mvn clean install'
}
}
}
Pipeline Syntax Page¶
Soooo, do I always have to figure out how to write these code snippets?
No, don't worry. You don't have to.
At every pipeline job type there is a link called "Pipeline Syntax".
This gives you a page with a drop down menu, from where you can select all the available steps.
Once you select a step, you can use the UI to setup the step and then use the generate button to give you the correct syntax.